2023
A Novel Control-Variates Approach for Performative Gradient-Based Learners with Missing Data
Xing Han, Jing Hu, Joydeep Ghosh
2023 International Joint Conference on Neural Networks (IJCNN)
We propose a new, principled approach to tackling missing data problems that can reduce both bias and variance of any (stochastic) gradient descent-based predictive model that is learned on such data. The proposed method can use an arbitrary (and potentially biased) imputation model to fill in the missing values, as it corrects the biases introduced by imputation with a control variates method, leading to an unbiased estimation for gradient updates. Theoretically, we prove that our control variates approach improves the convergence of stochastic gradient descent under common missing data settings. Empirically, we show that our method yields superior performance as compared to the results obtained using competing imputation methods, on various applications, across different missing data patterns.
A Novel Control-Variates Approach for Performative Gradient-Based Learners with Missing Data
Xing Han, Jing Hu, Joydeep Ghosh
2023 International Joint Conference on Neural Networks (IJCNN)
We propose a new, principled approach to tackling missing data problems that can reduce both bias and variance of any (stochastic) gradient descent-based predictive model that is learned on such data. The proposed method can use an arbitrary (and potentially biased) imputation model to fill in the missing values, as it corrects the biases introduced by imputation with a control variates method, leading to an unbiased estimation for gradient updates. Theoretically, we prove that our control variates approach improves the convergence of stochastic gradient descent under common missing data settings. Empirically, we show that our method yields superior performance as compared to the results obtained using competing imputation methods, on various applications, across different missing data patterns.
2022
Designing Robust Transformers using Robust Kernel Density Estimation
Xing Han, Tongzheng Ren, Tan Minh Nguyen, Khai Nguyen, Joydeep Ghosh, Nhat Ho
37th Conference on Neural Information Processing Systems (NeurIPS 2023)
Recent advances in Transformer architecture have empowered its empirical success in various tasks across different domains. However, existing works mainly focus on improving the standard accuracy and computational cost, without considering the robustness of contaminated samples. Existing work has shown that the self-attention mechanism, which is the center of the Transformer architecture, can be viewed as a non-parametric estimator based on the well-known kernel density estimation (KDE). This motivates us to leverage the robust kernel density estimation (RKDE) in the self-attention mechanism, to alleviate the issue of the contamination of data by down-weighting the weight of bad samples in the estimation process. The modified self-attention mechanism can be incorporated into different Transformer variants. Empirical results on language modeling and image classification tasks demonstrate the effectiveness of this approach.
Designing Robust Transformers using Robust Kernel Density Estimation
Xing Han, Tongzheng Ren, Tan Minh Nguyen, Khai Nguyen, Joydeep Ghosh, Nhat Ho
37th Conference on Neural Information Processing Systems (NeurIPS 2023)
Recent advances in Transformer architecture have empowered its empirical success in various tasks across different domains. However, existing works mainly focus on improving the standard accuracy and computational cost, without considering the robustness of contaminated samples. Existing work has shown that the self-attention mechanism, which is the center of the Transformer architecture, can be viewed as a non-parametric estimator based on the well-known kernel density estimation (KDE). This motivates us to leverage the robust kernel density estimation (RKDE) in the self-attention mechanism, to alleviate the issue of the contamination of data by down-weighting the weight of bad samples in the estimation process. The modified self-attention mechanism can be incorporated into different Transformer variants. Empirical results on language modeling and image classification tasks demonstrate the effectiveness of this approach.
Machine-learning based generation of text style variations for digital content items
Jessica Lundin, Owen Winne Schoppe, Xing Han, Michael Reynolds Sollami, Brian J. Lonsdorf, Alan Martin Ross, David J. Woodward, Sonke Rohde
US Patent 2022/0245322 A1
An online system generates a set of content item variations for a reference content item that include different styles of text for the content item. The different styles of text are generated by applying machine-learned style transfer models, for example, neural network based models to reference text of the reference content item. The text variations retain the textual content of the reference text but are synthesized with different styles. The online system can provide the content item variations to users on an online experimental platform to collect user interaction information that may indicate how users respond to different styles of text. The online system or the content providers can effectively target users with content items that include the style of text the users respond to based on the collected information.
Machine-learning based generation of text style variations for digital content items
Jessica Lundin, Owen Winne Schoppe, Xing Han, Michael Reynolds Sollami, Brian J. Lonsdorf, Alan Martin Ross, David J. Woodward, Sonke Rohde
US Patent 2022/0245322 A1
An online system generates a set of content item variations for a reference content item that include different styles of text for the content item. The different styles of text are generated by applying machine-learned style transfer models, for example, neural network based models to reference text of the reference content item. The text variations retain the textual content of the reference text but are synthesized with different styles. The online system can provide the content item variations to users on an online experimental platform to collect user interaction information that may indicate how users respond to different styles of text. The online system or the content providers can effectively target users with content items that include the style of text the users respond to based on the collected information.
Split Localized Conformal Prediction
Xing Han, Ziyang Tang, Joydeep Ghosh, Qiang Liu
ICML 2021 DFUQ Workshop
Conformal prediction is a simple and powerful tool that can quantify uncertainty without any distributional assumptions. However, existing methods can only provide an average coverage guarantee, which is not ideal compared to the stronger conditional coverage guarantee. Although achieving exact conditional coverage is proven to be impossible, approximating conditional coverage is still an important research direction. In this paper, we propose a modified non-conformity score by leveraging local approximation of the conditional distribution. The modified score inherits the spirit of split conformal methods, which is simple and efficient compared with full conformal methods but better approximates conditional coverage guarantee. Empirical results on various datasets, including a high dimension age regression on image, demonstrate that our method provides tighter intervals compared to existing methods.
Split Localized Conformal Prediction
Xing Han, Ziyang Tang, Joydeep Ghosh, Qiang Liu
ICML 2021 DFUQ Workshop
Conformal prediction is a simple and powerful tool that can quantify uncertainty without any distributional assumptions. However, existing methods can only provide an average coverage guarantee, which is not ideal compared to the stronger conditional coverage guarantee. Although achieving exact conditional coverage is proven to be impossible, approximating conditional coverage is still an important research direction. In this paper, we propose a modified non-conformity score by leveraging local approximation of the conditional distribution. The modified score inherits the spirit of split conformal methods, which is simple and efficient compared with full conformal methods but better approximates conditional coverage guarantee. Empirical results on various datasets, including a high dimension age regression on image, demonstrate that our method provides tighter intervals compared to existing methods.
Efficient Forecasting of Large Scale Hierarchical Time Series via Multilevel Clustering
Xing Han, Tongzheng Ren, Jing Hu, Joydeep Ghosh, Nhat Ho
9th International conference on Time Series and Forecasting
We propose a novel approach to cluster hierarchical time series (HTS) for efficient forecasting and data analysis. Inspired by a practically important but unstudied problem, we found that leveraging local information when clustering HTS will lead to better performance. The clustering procedure we proposed can cope with massive HTS with arbitrary lengths and structures. This method, besides providing better insights from the data, can also be used to accelerate the forecasts for a large number of HTS. Each time series is first assigned the forecast from its cluster representative, which can be considered as a ``shrinkage prior'' for the set of time series it represents. Then this base forecast can be quickly fine-tuned to adjust to the specifics of that time series. We empirically show that our method substantially improves performance for large-scale clustering and forecasting tasks involving much HTS.
Efficient Forecasting of Large Scale Hierarchical Time Series via Multilevel Clustering
Xing Han, Tongzheng Ren, Jing Hu, Joydeep Ghosh, Nhat Ho
9th International conference on Time Series and Forecasting
We propose a novel approach to cluster hierarchical time series (HTS) for efficient forecasting and data analysis. Inspired by a practically important but unstudied problem, we found that leveraging local information when clustering HTS will lead to better performance. The clustering procedure we proposed can cope with massive HTS with arbitrary lengths and structures. This method, besides providing better insights from the data, can also be used to accelerate the forecasts for a large number of HTS. Each time series is first assigned the forecast from its cluster representative, which can be considered as a ``shrinkage prior'' for the set of time series it represents. Then this base forecast can be quickly fine-tuned to adjust to the specifics of that time series. We empirically show that our method substantially improves performance for large-scale clustering and forecasting tasks involving much HTS.
Architecture Agnostic Federated Learning for Neural Networks
Disha Makhija, Xing Han, Nhat Ho, Joydeep Ghosh
Proceedings of the 39th International Conference on Machine Learning (ICML) 2022
With growing concerns regarding data privacy and rapid increase in data volume, Federated Learning (FL) has become an important learning paradigm. However, jointly learning a deep neural network model in a FL setting proves to be a non-trivial task because of the complexities associated with the neural networks, such as varied architectures across clients, permutation invariance of the neurons, and presence of non-linear transformations in each layer. This work introduces a novel framework, Federated Heterogeneous Neural Networks (FedHeNN), that allows each client to build a personalised model without enforcing a common architecture across clients. This allows each client to optimize with respect to local data and compute constraints, while still benefiting from the learnings of other (potentially more powerful) clients. The key idea of FedHeNN is to use the instance-level representations obtained from peer clients to guide the simultaneous training on each client. The extensive experimental results demonstrate that the FedHeNN framework is capable of learning better performing models on clients in both the settings of homogeneous and heterogeneous architectures across clients.
Architecture Agnostic Federated Learning for Neural Networks
Disha Makhija, Xing Han, Nhat Ho, Joydeep Ghosh
Proceedings of the 39th International Conference on Machine Learning (ICML) 2022
With growing concerns regarding data privacy and rapid increase in data volume, Federated Learning (FL) has become an important learning paradigm. However, jointly learning a deep neural network model in a FL setting proves to be a non-trivial task because of the complexities associated with the neural networks, such as varied architectures across clients, permutation invariance of the neurons, and presence of non-linear transformations in each layer. This work introduces a novel framework, Federated Heterogeneous Neural Networks (FedHeNN), that allows each client to build a personalised model without enforcing a common architecture across clients. This allows each client to optimize with respect to local data and compute constraints, while still benefiting from the learnings of other (potentially more powerful) clients. The key idea of FedHeNN is to use the instance-level representations obtained from peer clients to guide the simultaneous training on each client. The extensive experimental results demonstrate that the FedHeNN framework is capable of learning better performing models on clients in both the settings of homogeneous and heterogeneous architectures across clients.
2021
Dynamic Combination of Heterogeneous Models for Hierarchical Time Series
Xing Han, Jing Hu, Joydeep Ghosh
ICDM 2022 Workshop
We introduce a framework to dynamically combine heterogeneous models called DYCHEM, which forecasts a set of time series that are related through an aggregation hierarchy. Different types of forecasting models can be employed as individual "experts" so that each model is tailored to the nature of the corresponding time series. DYCHEM learns hierarchical structures during the training stage to help generalize better across all the time series being modeled and also mitigates coherency issues that arise due to constraints imposed by the hierarchy. To improve the reliability of forecasts, we construct quantile estimations based on the point forecasts obtained from combined heterogeneous models. The resulting quantile forecasts are nearly coherent and independent of the choice of forecasting models. We conduct a comprehensive evaluation of both point and quantile forecasts for hierarchical time series (HTS), including public data and user records from a large financial software company. In general, our method is robust, adaptive to datasets with different properties, and highly configurable and efficient for large-scale forecasting pipelines.
Dynamic Combination of Heterogeneous Models for Hierarchical Time Series
Xing Han, Jing Hu, Joydeep Ghosh
ICDM 2022 Workshop
We introduce a framework to dynamically combine heterogeneous models called DYCHEM, which forecasts a set of time series that are related through an aggregation hierarchy. Different types of forecasting models can be employed as individual "experts" so that each model is tailored to the nature of the corresponding time series. DYCHEM learns hierarchical structures during the training stage to help generalize better across all the time series being modeled and also mitigates coherency issues that arise due to constraints imposed by the hierarchy. To improve the reliability of forecasts, we construct quantile estimations based on the point forecasts obtained from combined heterogeneous models. The resulting quantile forecasts are nearly coherent and independent of the choice of forecasting models. We conduct a comprehensive evaluation of both point and quantile forecasts for hierarchical time series (HTS), including public data and user records from a large financial software company. In general, our method is robust, adaptive to datasets with different properties, and highly configurable and efficient for large-scale forecasting pipelines.
Multi-Pair Text Style Transfer for Unbalanced Data via Task-Adaptive Meta-Learning
Xing Han, Jessica Lundin
Proceedings of the 1st ACL Workshop on Meta Learning and Its Applications to Natural Language Processing
Text-style transfer aims to convert text given in one domain into another by paraphrasing the sentence or substituting the keywords without altering the content. By necessity, state-of-the-art methods have evolved to accommodate nonparallel training data, as it is frequently the case there are multiple data sources of unequal size, with a mixture of labeled and unlabeled sentences. Moreover, the inherent style defined within each source might be distinct. A generic bidirectional (e.g., formal ⇔ informal) style transfer regardless of different groups may not generalize well to different applications. In this work, we developed a task adaptive meta-learning framework that can simultaneously perform a multi-pair text-style transfer using a single model. The proposed method can adaptively balance the difference of meta-knowledge across multiple tasks. Results show that our method leads to better quantitative performance as well as coherent style variations. Common challenges of unbalanced data and mismatched domains are handled well by this method.
Multi-Pair Text Style Transfer for Unbalanced Data via Task-Adaptive Meta-Learning
Xing Han, Jessica Lundin
Proceedings of the 1st ACL Workshop on Meta Learning and Its Applications to Natural Language Processing
Text-style transfer aims to convert text given in one domain into another by paraphrasing the sentence or substituting the keywords without altering the content. By necessity, state-of-the-art methods have evolved to accommodate nonparallel training data, as it is frequently the case there are multiple data sources of unequal size, with a mixture of labeled and unlabeled sentences. Moreover, the inherent style defined within each source might be distinct. A generic bidirectional (e.g., formal ⇔ informal) style transfer regardless of different groups may not generalize well to different applications. In this work, we developed a task adaptive meta-learning framework that can simultaneously perform a multi-pair text-style transfer using a single model. The proposed method can adaptively balance the difference of meta-knowledge across multiple tasks. Results show that our method leads to better quantitative performance as well as coherent style variations. Common challenges of unbalanced data and mismatched domains are handled well by this method.
Model-Agnostic Explanations using Minimal Forcing Subsets
Xing Han, Joydeep Ghosh
2021 International Joint Conference on Neural Networks (IJCNN)
How can we find a subset of training samples that are most responsible for a specific prediction made by a complex black-box machine learning model? More generally, how can we explain the model's decisions to end-users in a transparent way? We propose a new model-agnostic algorithm to identify a minimal set of training samples that are indispensable for a given model's decision at a particular test point, i.e., the model's decision would have changed upon the removal of this subset from the training dataset. Our algorithm identifies such a set of ``indispensable'' samples iteratively by solving a constrained optimization problem. Further, we speed up the algorithm through efficient approximations and provide theoretical justification for its performance. To demonstrate the applicability and effectiveness of our approach, we apply it to a variety of tasks including data poisoning detection, training set debugging and understanding loan decisions. The results show that our algorithm is an effective and easy-to-comprehend tool that helps to better understand local model behavior, and therefore facilitates the adoption of machine learning in domains where such understanding is a requisite.
Model-Agnostic Explanations using Minimal Forcing Subsets
Xing Han, Joydeep Ghosh
2021 International Joint Conference on Neural Networks (IJCNN)
How can we find a subset of training samples that are most responsible for a specific prediction made by a complex black-box machine learning model? More generally, how can we explain the model's decisions to end-users in a transparent way? We propose a new model-agnostic algorithm to identify a minimal set of training samples that are indispensable for a given model's decision at a particular test point, i.e., the model's decision would have changed upon the removal of this subset from the training dataset. Our algorithm identifies such a set of ``indispensable'' samples iteratively by solving a constrained optimization problem. Further, we speed up the algorithm through efficient approximations and provide theoretical justification for its performance. To demonstrate the applicability and effectiveness of our approach, we apply it to a variety of tasks including data poisoning detection, training set debugging and understanding loan decisions. The results show that our algorithm is an effective and easy-to-comprehend tool that helps to better understand local model behavior, and therefore facilitates the adoption of machine learning in domains where such understanding is a requisite.
Simultaneously Reconciled Quantile Forecasting of Hierarchically Related Time Series
Xing Han, Sambarta Dasgupta, Joydeep Ghosh
Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS) 2021
Many real-life applications involve simultaneously forecasting multiple time series that are hierarchically related via aggregation or disaggregation operations. For instance, commercial organizations often want to forecast inventories simultaneously at store, city, and state levels for resource planning purposes. In such applications, it is important that the forecasts, in addition to being reasonably accurate, are also consistent w.r.t one another. Although forecasting such hierarchical time series has been pursued by economists and data scientists, the current state-of-the-art models use strong assumptions, e.g., all forecasts being unbiased estimates, noise distribution being Gaussian. Besides, state-of-the-art models have not harnessed the power of modern nonlinear models, especially ones based on deep learning. In this paper, we propose using a flexible nonlinear model that optimizes quantile regression loss coupled with suitable regularization terms to maintain the consistency of forecasts across hierarchies. The theoretical framework introduced herein can be applied to any forecasting model with an underlying differentiable loss function. A proof of optimality of our proposed method is also provided. Simulation studies over a range of datasets highlight the efficacy of our approach.
Simultaneously Reconciled Quantile Forecasting of Hierarchically Related Time Series
Xing Han, Sambarta Dasgupta, Joydeep Ghosh
Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS) 2021
Many real-life applications involve simultaneously forecasting multiple time series that are hierarchically related via aggregation or disaggregation operations. For instance, commercial organizations often want to forecast inventories simultaneously at store, city, and state levels for resource planning purposes. In such applications, it is important that the forecasts, in addition to being reasonably accurate, are also consistent w.r.t one another. Although forecasting such hierarchical time series has been pursued by economists and data scientists, the current state-of-the-art models use strong assumptions, e.g., all forecasts being unbiased estimates, noise distribution being Gaussian. Besides, state-of-the-art models have not harnessed the power of modern nonlinear models, especially ones based on deep learning. In this paper, we propose using a flexible nonlinear model that optimizes quantile regression loss coupled with suitable regularization terms to maintain the consistency of forecasts across hierarchies. The theoretical framework introduced herein can be applied to any forecasting model with an underlying differentiable loss function. A proof of optimality of our proposed method is also provided. Simulation studies over a range of datasets highlight the efficacy of our approach.
2020
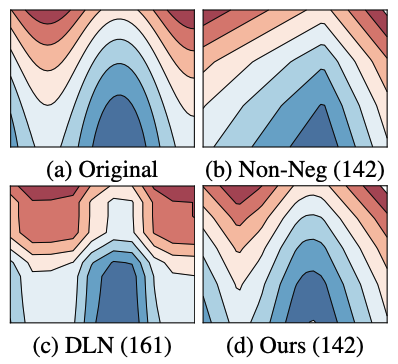
Certified Monotonic Neural Networks
Xingchao Liu, Xing Han, Na Zhang, Qiang Liu
34th Conference on Neural Information Processing Systems (NeurIPS 2020)Spotlight
Learning monotonic models with respect to a subset of the inputs is a desirable feature to effectively address the fairness, interpretability, and generalization issues in practice. Existing methods for learning monotonic neural networks either require specifically designed model structures to ensure monotonicity, which can be too restrictive/complicated, or enforce monotonicity by adjusting the learning process, which cannot provably guarantee the learned model is monotonic on selected features. In this work, we propose to certify the monotonicity of the general piece-wise linear neural networks by solving a mixed integer linear programming problem. This provides a new general approach for learning monotonic neural networks with arbitrary model structures. Our method allows us to train neural networks with heuristic monotonicity regularizations, and we can gradually increase the regularization magnitude until the learned network is certified monotonic. Compared to prior work, our method does not require human-designed constraints on the weight space and also yields more accurate approximation. Empirical studies on various datasets demonstrate the efficiency of our approach over the state-of-the-art methods, such as Deep Lattice Networks.
Certified Monotonic Neural Networks
Xingchao Liu, Xing Han, Na Zhang, Qiang Liu
34th Conference on Neural Information Processing Systems (NeurIPS 2020)Spotlight
Learning monotonic models with respect to a subset of the inputs is a desirable feature to effectively address the fairness, interpretability, and generalization issues in practice. Existing methods for learning monotonic neural networks either require specifically designed model structures to ensure monotonicity, which can be too restrictive/complicated, or enforce monotonicity by adjusting the learning process, which cannot provably guarantee the learned model is monotonic on selected features. In this work, we propose to certify the monotonicity of the general piece-wise linear neural networks by solving a mixed integer linear programming problem. This provides a new general approach for learning monotonic neural networks with arbitrary model structures. Our method allows us to train neural networks with heuristic monotonicity regularizations, and we can gradually increase the regularization magnitude until the learned network is certified monotonic. Compared to prior work, our method does not require human-designed constraints on the weight space and also yields more accurate approximation. Empirical studies on various datasets demonstrate the efficiency of our approach over the state-of-the-art methods, such as Deep Lattice Networks.
2019
Sensing Personality to Predict Job Performance
Suwen Lin, Stephen M. Mattingly, Xing Han
CHI Future of Work Workshop 2019
The proliferation of sensors allows for continuous capturing an individual's physical, social, and environmental contexts. We apply machine learning to sensor-collected data to analyze and predict personality, a factor known to influence job performance. Based on our work in Tesserae project, an ongoing study of 757 workers in multi-companies, we present the initial results for passively assessing the worker personality and performance. Our work opens the way of how pervasive technologies track performance in work environment.
Sensing Personality to Predict Job Performance
Suwen Lin, Stephen M. Mattingly, Xing Han
CHI Future of Work Workshop 2019
The proliferation of sensors allows for continuous capturing an individual's physical, social, and environmental contexts. We apply machine learning to sensor-collected data to analyze and predict personality, a factor known to influence job performance. Based on our work in Tesserae project, an ongoing study of 757 workers in multi-companies, we present the initial results for passively assessing the worker personality and performance. Our work opens the way of how pervasive technologies track performance in work environment.